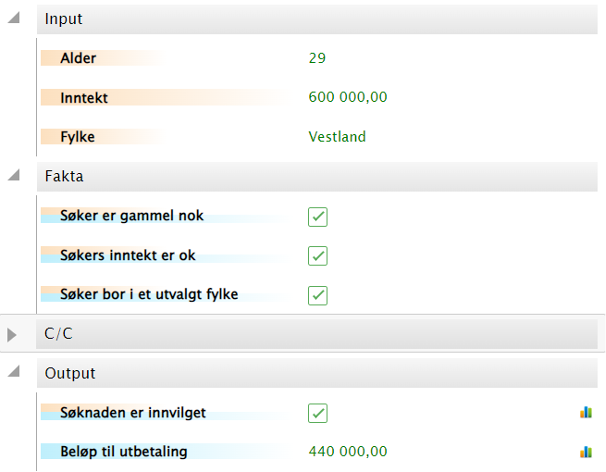
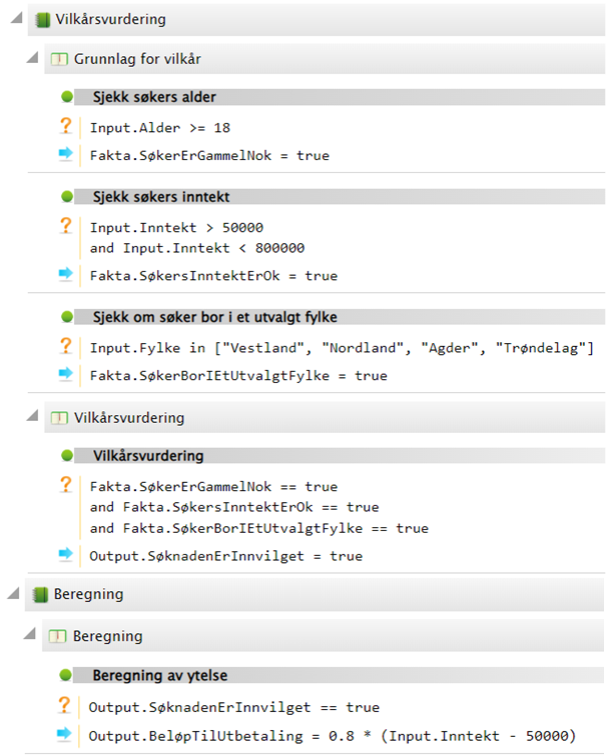
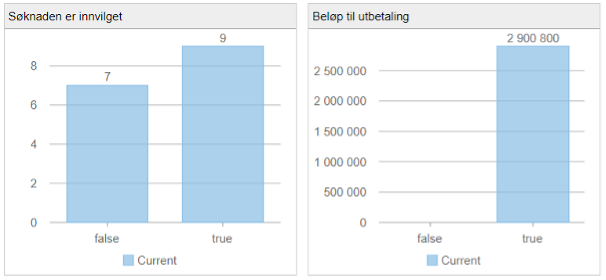
Innledning
SMARTS er et beslutningsstyringssystem (Decision Intelligence Platform, DIP) utviklet av Sparkling Logic. Systemet er designet for å optimalisere og automatisere beslutningsprosesser innenfor organisasjoner ved å tillate rask implementering, testing og endring av kompleks beslutningslogikk. I denne bloggposten bruker jeg SMARTS som eksempel, men teksten vil i stor grad kunne være relevant om man vurderer andre systemer også. I den første delen av innlegget vil jeg presentere noen nøkkelegenskaper og fordeler ved bruk av SMARTS, før jeg lenger ned beskriver sentrale prinsipper for implementering av beslutninger.
Her er noen nøkkelegenskaper og fordeler ved å bruke SMARTS:
Sentralisert beslutningslogikk
SMARTS hjelper organisasjoner med å sentralisere beslutningslogikken, noe som forenkler vedlikehold og oppdatering. Dette er spesielt nyttig i miljøer hvor beslutningsreglene endres ofte som respons på nye forretningskrav eller ekstern regulering fra f.eks. Stortinget eller et departement.
Tilgjengelighet for ikke-tekniske brukere
En av de mest fremtredende egenskapene til SMARTS er hvor tilgjengelig systemet er for ikke-teknisk personell. Plattformen tilbyr et brukervennlig grensesnitt for regelutforming, noe som lar både forretningsanalytikere, regeladministratorer, og andre ikke-tekniske roller bidra til utvikling og vedlikehold av beslutningslogikken uten dyptgående programmeringskunnskap. Ansatte med disse rollene får større eierskap til løsningen når de kan jobbe i den selv. Dette bidrar også til større trygghet i at man forvalter regelverket riktig og at automatikken fatter riktige beslutninger.
Fleksibilitet og skalerbarhet
SMARTS er bygget for å være fleksibelt og kan skaleres for å møte behovene til både små og store organisasjoner. Systemet kan distribueres i skyen (på plattformer som AWS, Azure, GCP, OpenShift) eller on-premise, avhengig av organisasjonens preferanser og krav til datasikkerhet.
Avanserte analysefunksjoner
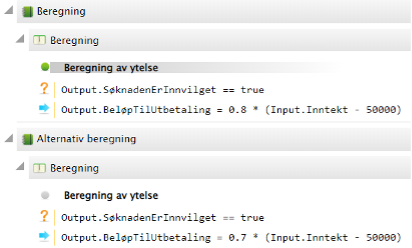
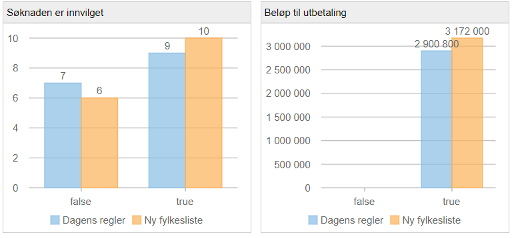
SMARTS inneholder avanserte analysefunksjoner og simuleringsverktøy som lar brukere teste og evaluere beslutningslogikken før den settes i produksjon. Dette bidrar til å redusere risikoen og øke tilliten til beslutningene som systemet genererer. Øystein Grøndahl har tidligere skrevet om mulighetene for å vurdere konsekvenser av regelendringer, se A-B testing i SMARTS: Del 1 og A-B testing i SMARTS: Del 2.
Integrasjon med moderne teknologier
Med støtte for HTTP APIer og tilgang til et Software Development Kit (SDK), kan SMARTS enkelt integreres med eksisterende IT-infrastruktur og applikasjoner. Dette sikrer en sømløs flyt av data og beslutninger gjennom organisasjonens økosystem.
Sikkerhet og compliance
Sikkerhet og compliance er kritiske aspekter for alle beslutningssystemer. SMARTS støtter sikkerhetsstandarder og autentiseringsprotokoller for å sikre dataintegritet og tilgangskontroll, samt evnen til å implementere zero trust-prinsipper gjennom bruk av kortlivede tokens. SMARTS lagrer SMARTS aldri data, heller ikke når reglene blir kjørt.
Prinsipper for implementasjon av beslutninger
Etter å ha brukt SMARTS i flere prosjekter er det noen sentrale prinsipper det er lurt å tenke på når man implementerer beslutningstjenester. Disse prinsippene sikrer at beslutningstjenestene er robuste, vedlikeholdbare og lett integrerbare i ulike forretningsprosesser. Prinsippene kan også benyttes når man velger å implementere regler i programmeringsspråkene som en virksomhet benytter til vanlig, dette kan typisk være Java, C#, Kotlin eller Python.
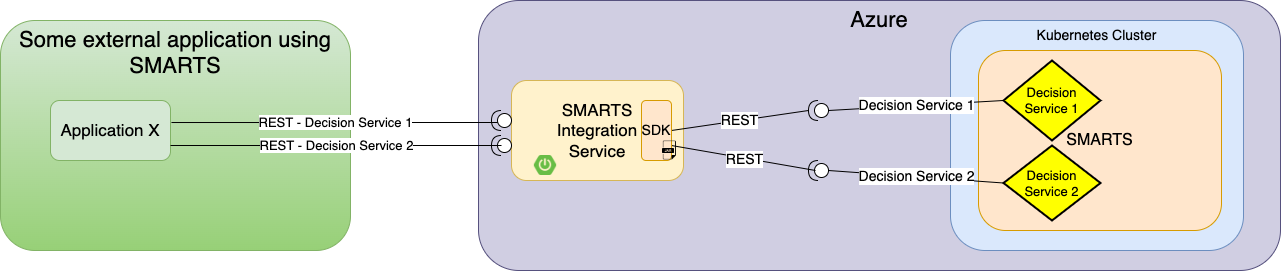
Figuren nedenfor viser et mulig eksempel på hvordan SMARTS kan integreres i en løsning:
Beslutninger bør være tilstandsløse
Beslutninger bør ikke håndtere eller initiere oppdateringer av andre objekter eller ressurser. Ansvaret for slike oppdateringer bør ligge hos den prosessen som benytter resultatet av beslutningen. Dette forenkler beslutningstjenestene og sikrer at de utelukkende er dedikert til beslutningstaking.
Beslutningstjenester bør være uavhengige av prosesser og systemer
Ved å designe beslutningstjenester som er uavhengige av spesifikke prosesser og systemer, øker potensialet for å kunne gjenbruke tjenestene på tvers av ulike deler av organisasjonen. Dette fører til at man også støtter sentralisering av regelverket, noe som fører til likebehandling og lettere vedlikehold og oppdatering av regler.
Bruk gjenkjennelige begreper
Beslutningene bør implementeres ved hjelp av begreper og terminologier som er lett gjenkjennelige og direkte avledet fra regelspesifikasjonen og den tilhørende faktamodellen. Dette styrker forståelsen og overholdelsen av reglene gjennom hele organisasjonen.
Det finnes flere initiativ for å beskrive beslutninger og forretningsregler på en strukturert måte. Formålet er både å standardisere måten regler beskrives på, samtidig som man også muliggjør verktøystøtte. Her er noen lenker som kan være av interesse:
- https://www.decisionmanagementsolutions.com/wp-content/uploads/2014/11/Manifesto-White-Paper-October-7.pdf
- https://decisionmanagementsolutions.com/wp-content/uploads/2019/10/The-Decision-Management-Manifesto-October-6-2019-Norwegian.pdf
- https://en.wikipedia.org/wiki/Decision_Model_and_Notation
- https://en.wikipedia.org/wiki/Semantics_of_Business_Vocabulary_and_Business_Rules
- https://www.rulespeak.com/no/
Modellbasert input og output
Input og output for beslutninger kan integreres med modeller som allerede er i bruk i organisasjonen. Dette bidrar til enkel integrasjon og dataflyt.
Det er nødvendig å etablere en klar og pålitelig mappingprosess mellom de eksisterende modellene og den interne faktamodellen som beslutningstjenesten bruker. Denne mappingen bør gjøres i selve beslutningen (altså før og etter selve regelevalueringen skjer).
Dokumentasjon og vedlikehold
Effektiv dokumentasjon av beslutningslogikken og hvordan denne er implementert er kritisk for vedlikehold og fremtidige revisjoner. Dette inkluderer regeldokumentasjon, endringshistorikk og systemdokumentasjon.
Testing og validering
Systematisk testing og validering av beslutningstjenester er essensielt for å sikre at de fungerer som forventet under ulike scenarier. Dette inkluderer enhetstesting, integrasjonstesting og ende-til-ende testing.
Oppsummering
Samlet sett tilbyr SMARTS en robust, fleksibel og brukervennlig plattform for beslutningsstyring som kan tilpasses en rekke brukstilfeller, fra finansielle tjenester, detaljhandel, og mer. Og ikke minst for offentlig forvaltning hvor lovverk og forskrifter er grunnleggende i mange av systemene. SMARTS evne til å gjøre beslutninger tilgjengelig for ikke-teknisk personell, samtidig som systemet opprettholder høye standarder for sikkerhet og compliance, gjør det til en verdifull ressurs for enhver organisasjon som ser etter å optimalisere sine beslutningsprosesser.
Ved å følge prinsippene for implementering av beslutninger som jeg har beskrevet ovenfor, kan organisasjoner utvikle effektive og pålitelige beslutningsstyringssystemer som er både robuste og fleksible nok til å møte de stadig skiftende kravene i en dynamisk forretningsverden.