«Innen 2026 vil over 70 % av offentlige organisasjoner bruke kunstig intelligens for å styrke menneskelig beslutningstaking i administrasjonen.»
– Gartner (1)
Denne utviklingen understreker behovet for teknologier som Decision Intelligence, ikke som en erstatning for mennesker, men som et verktøy i samspillet mellom menneskelig vurdering og automatisert beslutningsstøtte.
Offentlig sektor opererer ofte i komplekse landskap preget av regelverk, ressursbegrensninger og høye forventninger fra innbyggere. Lange saksbehandlingstider, manuelle prosesser og tidkrevende vurderinger gjør at mange ansatte bruker verdifull tid på beslutninger som burde vært automatisert.
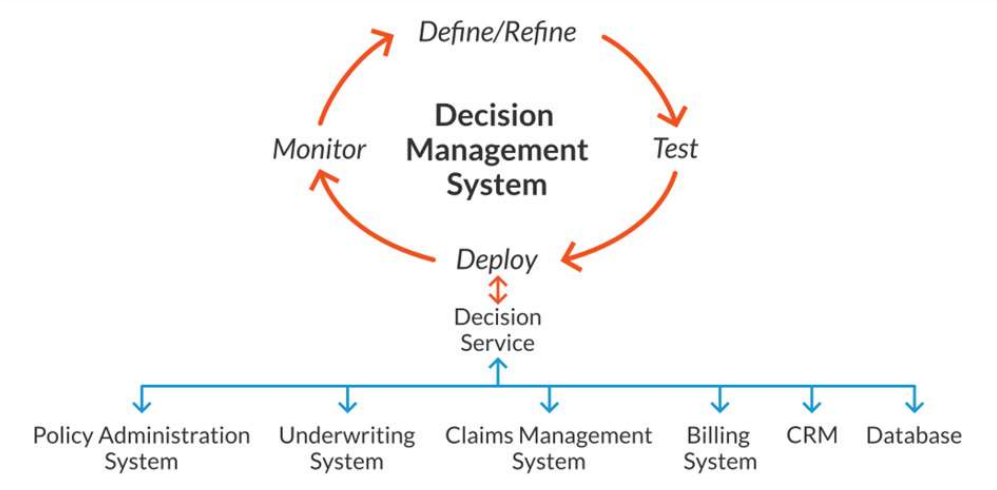
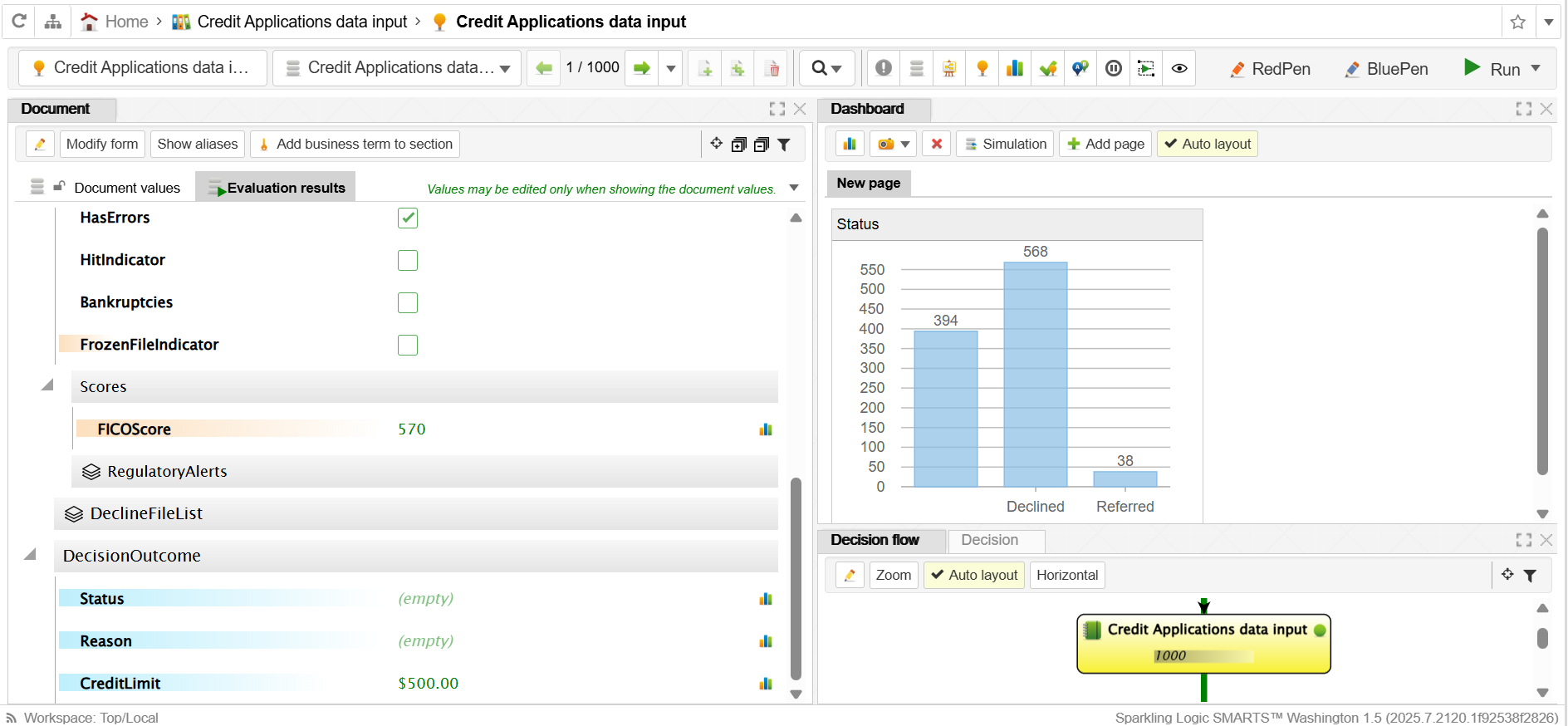
SMARTS automatiserer komplekse beslutninger i sektorer med regelmessige endringer i lover og regler. Siden plattformen er bygget som en low-code/no-code-løsning, kan fagpersoner selv vedlikeholde og endre beslutningslogikk, uten hjelp fra IT. Dermed kan ulike fagområder aktivt bidra i utviklingen av beslutningsregler i én felles plattform.
Bruksområder i offentlig sektor
Automatisert saksbehandling
Ved å automatisere beslutningsprosesser i SMARTS får offentlig sektor tilgang til en plattform som kombinerer regelstyrt logikk med Kunstig Intelligens (KI) for å håndtere saksbehandlinger mer effektivt og presist. I en hverdag der volumet av saker øker og kompleksiteten varierer gir SMARTS mulighet til å modellere beslutningslogikk direkte i systemet, samtidig som KI funksjonaliteter bidrar til å identifisere mønstre, foreslå optimal beslutningsflyt og avdekke avvik.
Saksbehandlere får støtte til å ta riktige vurderinger gjennom et beslutningsstøttesystem som håndterer store mengder saker med høy presisjon. Endringer i beslutningsgrunnlag eller prioriteringer kan implementeres raskt, noe som gir høy grad av fleksibilitet ved behovsendringer.
Compliance & overholdelse av regelverk
Uten gode prosesser og klare rammer kan compliance og etterlevelse bli både tidkrevende og uforutsigbart. Spesielt ved lovendringer og stadig strengere krav til dokumentasjon og sporbarhet. Fallgruver kan være ulik praksis, manglende dokumentasjon og vanskeligheter med å forklare beslutningsgrunnlag i ettertid
Mange offentlige virksomheter forsøker å holde beslutningsgrunnlaget oppdatert i interne systemer, og med det sikre at innbyggere behandles likt og rettferdig. Men når prosessene er manuelle eller fragmenterte, kan det være krevende å dokumentere beslutninger og endringer på en sporbar og konsistent måte – særlig når flere avdelinger er involvert.
SMARTS møter disse utfordringene ved å implementere beslutningslogikk direkte i systemet, slik at vurderinger alltid følger gjeldende praksis og prioriteringer. Alle beslutninger og den underliggende logikken dokumenteres og gjøres sporbare, noe som gir både innsikt og trygghet. Regelendringer og justeringer kan gjøres raskt og uten hjelp fra IT-avdelingen, noe som gir offentlig sektor en skalerbar og fremtidsrettet måte å håndtere saksbehandling på.
Ressursprioritering & kapasitetsstyring
Mange offentlige virksomheter mangler i dag datadrevne verktøy som gir innsikt i hvor tiltak har størst effekt, og dette fører ofte til at tid og budsjett brukes på en lite målrettet måte. Ressurser fordeles etter faste rutiner eller historiske mønstre, og er ikke basert på reelle behov og endringer.
SMARTS kombinerer regelstyrt beslutningslogikk og med KI-funksjonalitet for å analysere store datamengder og identifisere mønstre, avvik og prioriteringsmuligheter. Systemet kan for eksempel avdekke hvilke områder som har størst behov for oppfølging, hvilke søknadstyper som skaper flaskehalser, eller hvor saksbehandlingstiden er lengst. Denne innsikten kan brukes av fagansvarlige til å justere beslutningsregler og ressursbruk løpende, uten at det krever omfattende systemendringer eller involvering fra IT-avdelingen.
Resultatet er en mer datadrevet og effektiv offentlig tjenesteyting, der innsatsen settes inn der den gir mest verdi. SMARTS gir dermed et grunnlag for bedre ressursutnyttelse og en mer datadrevet forvaltning.
Tildeling av tilskudd & støtteordninger
Når det gjelder tilskudd må offentlige organisasjoner sikre at midler fordeles i tråd med regelverk og politiske føringer, samtidig som søknader behandles likt. Løsningen må tilfredsstille et komplekst regelsett og sørge for at alle tilskudd er korrekt kalkulert, lovlig og overført til korrekt mottaker.
Mange sliter med manuelle prosesser, varierende praksis og utfordringer med å dokumentere beslutningsgrunnlaget. Med SMARTS kan tilskuddsprosesser automatiseres og standardiseres. Endringer i regelverk eller politiske føringer kan implementeres raskt slik at man får en transparent tilskuddsforvaltning, der både søkere og forvaltningen får bedre oversikt og forutsigbarhet.
(1) Gartner Announces the Top Government Technology Trends for 2024

Bruksområder
Saksbehandling
Ressursprioritering & kapasitetsstyring
Compliance & overholdelse av regelverk
Innbyggerkommunikasjon
Tildeling av tilskudd & støtteordninger
Roller
CIO / CDO / CTO
Compliance & Risk Officer
Forretningsanalyse team
Data & analyse team
Jurister
Saksbehandlere
IMDi kundehistorie
Les om hvordan Decisive implementerre SMARTS hos IMDi som nå har et effektivt og brukervennlig beslutningsstøttesystem.